 问题与挑战
问题与挑战

 随着互联网、云计算、移动互联、物联网等技术的发展,数以亿计的用户、智能终端、传感器等分秒都在产生数据,持续累积的海量数据中蕴含宝贵的数据价值,促使以数据的采集、处理和展现为主要研究内容的大数据处理技术的快速发展。然而由于数据量巨大,数据类型多样、处理性能要求极高的特点,大数据处理技术首先要考虑存储系统的架构与实现,确保数据可靠存储高效访问。
随着互联网、云计算、移动互联、物联网等技术的发展,数以亿计的用户、智能终端、传感器等分秒都在产生数据,持续累积的海量数据中蕴含宝贵的数据价值,促使以数据的采集、处理和展现为主要研究内容的大数据处理技术的快速发展。然而由于数据量巨大,数据类型多样、处理性能要求极高的特点,大数据处理技术首先要考虑存储系统的架构与实现,确保数据可靠存储高效访问。
 极高性能要求
极高性能要求
离线处理方式已无法满足当前业务需求,实时计算、流数据处理正在成为主流,数据的采集、处理、展现均对存储性能提出极高要求;大数据处理框架通常规模巨大,处理作业大量并发,要求极高的聚合吞吐率,存储性能面临更大挑战。
 数据总量巨大
数据总量巨大
随着互联网用户、移动终端、传感器设备等数量快速增长,需要处理的数据爆炸式增长,并随时间持续累积,例如,大型网站的用户日志数据量可达每日百TB,因此,存储系统支持PB级甚至EB级数据的高效存储是进行数据处理的前提。
 数据类型多样
数据类型多样
大数据处理应用类型众多,数据来源丰富、采集方式各异,数据类型涵盖结构化数据、文本、日志、图像、视频等,同时,不同大数据处理框架(如Hadoop、Storm、Spark等)对存储访问接口、数据访问模式的要求也不尽相同。
 高度扩展要求
高度扩展要求
随着业务的不断发展,数据量持续增大,数据处理规模的扩展在所难免,大数据处理平台多采用分布式架构,计算力的提升可通过扩展处理节点实现,存储系统也应具有在线扩展能力,可按需匹配数据量攀升导致的存储容量和性能需求。
解决方案
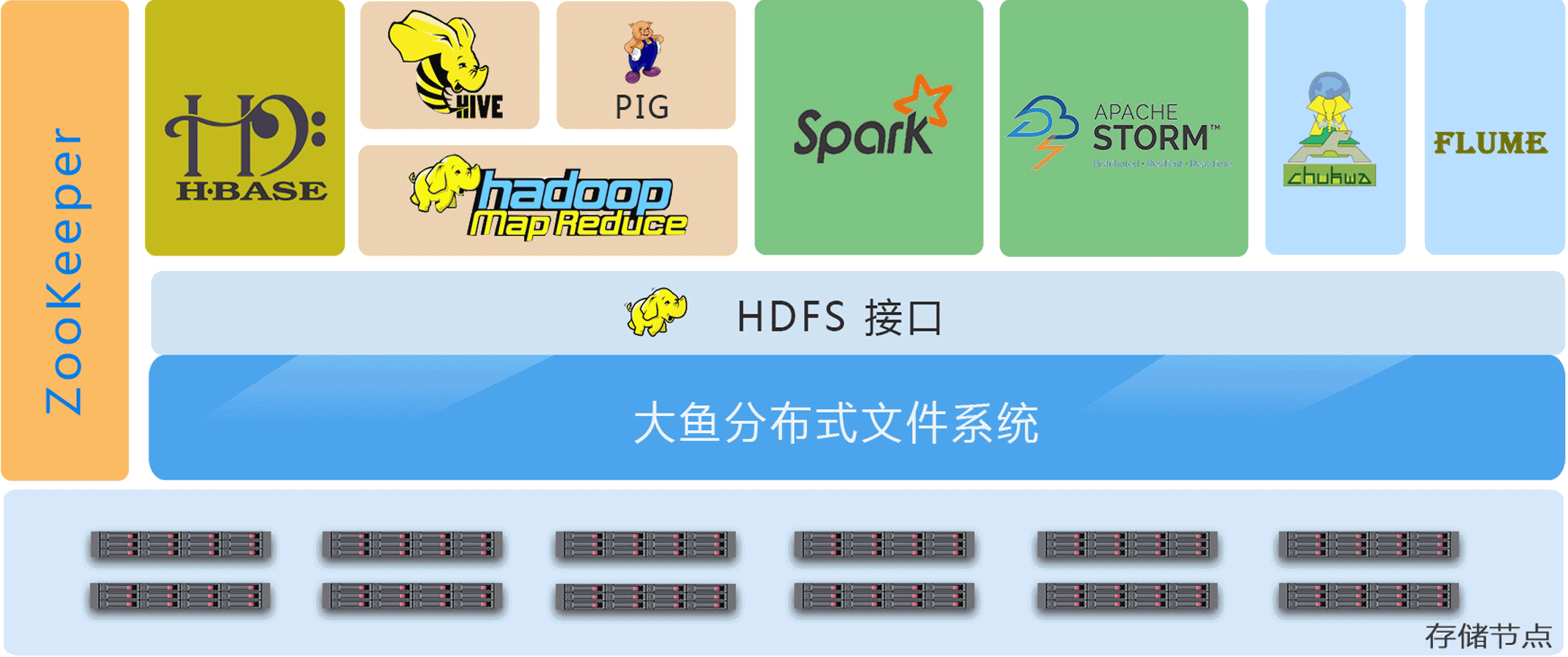
 高可扩展架构
高可扩展架构
模块化Scale-out架构,容量和性能均可通过节点堆叠而线性扩展,系统节点数目可在线平滑扩充至数千台, 提供EB级存储容量和数百GB聚合I/O带宽,有效支撑大数据存储与处理。
 匹配性能需求
匹配性能需求
存储系统性能随节点数目扩展,高效应对海量数据的大规模并发处理;可与主流大数据处理框架整合部署,构建存储/计算一体化处理平台,共享硬件资源,优化数据读写,消除存储网络瓶颈,数据处理性能倍增。
 丰富访问接口
丰富访问接口
提供HDFS插件,完美对接Hadoop/Spark /Storm等数据处理平台,以及Flume/Chukwa等数据采集工具;支持多种语言的编程接口, 高效对接数据处理应用;提供多种接口的POSIX文件访问, 同时兼容传统数据处理应用。
 通用硬件平台
通用硬件平台
采用普通商用服务器、主流互连网络搭建,无需昂贵的专有设备; 支持高速SSD与低成本大容量SATA/SAS磁盘混插, 兼顾性能与成本;与主流大数据处理框架的硬件平台需求相同,可整合部署,降低总体拥有成本。
方案亮点

HDFS插件
实现了基于原生Java API之上的HDFS插件,完美模拟HDFS系统,针对应用特别优化,解决HDFS性能问题,可高效支持各类Hadoop应用。

分布式集群架构
有别于传统存储系统,与主流分布式大数据处理框架采用相同设计原理,均为基于普通硬件的集群式架构,可实现系统级整合,具有超高扩展能力。
成本可控
通用硬件平台、主流网络支持,大幅降低构建成本;模块式横向扩展,扩展成本低廉可控;存储即计算的融合架构,硬件资源复用,数据处理系统成本骤降。